Un thread è la più piccola unità di esecuzione schedulabile da un sistema operativo. Rappresenta un flusso sequenziale di istruzioni che viene eseguito all’interno di un processo. Ogni thread è caratterizzato da:
- un program counter, che indica l’istruzione corrente,
- uno stack privato, per la gestione delle chiamate di funzione e delle variabili locali,
- un set di registri della CPU,
- un identificatore univoco.
KERNEL THREAD
Un kernel thread è un thread gestito direttamente dal kernel del sistema operativo. Il kernel mantiene le informazioni di scheduling e può assegnare ogni kernel thread a un core distinto, permettendo vero parallelismo su sistemi multi-core. Le operazioni di creazione, sincronizzazione e context switch hanno un costo maggiore, poiché richiedono l’intervento del kernel.
USER THREAD
Un user thread è un thread gestito interamente in spazio utente da una libreria di threading. Il kernel non è a conoscenza dei singoli user thread e vede il processo come un’unica entità schedulabile. Per questo motivo i context switch sono più leggeri, ma non è possibile ottenere parallelismo reale se tutti i thread sono mappati su un solo kernel thread, e il blocco di uno può bloccare l’intero processo.
MULTI-THREADING
L’utilizzo dei thread risulta essere particolarmente utile nel caso in cui un processo deve svolgere più attività indipendenti l’una dall’altra. In particolare, nel caso in cui un’attività richieda che il processo si blocchi, utilizzando più thread viene concesso alle altre attività di continuare ad essere svolte senza dover aspettare l’attività bloccata. I thread appartenenti allo stesso processo condividono le risorse del processo, tra cui:
- lo spazio di indirizzamento,
- il codice del programma,
- i dati globali e l’heap,
- le risorse di sistema (file aperti, socket, ecc.).
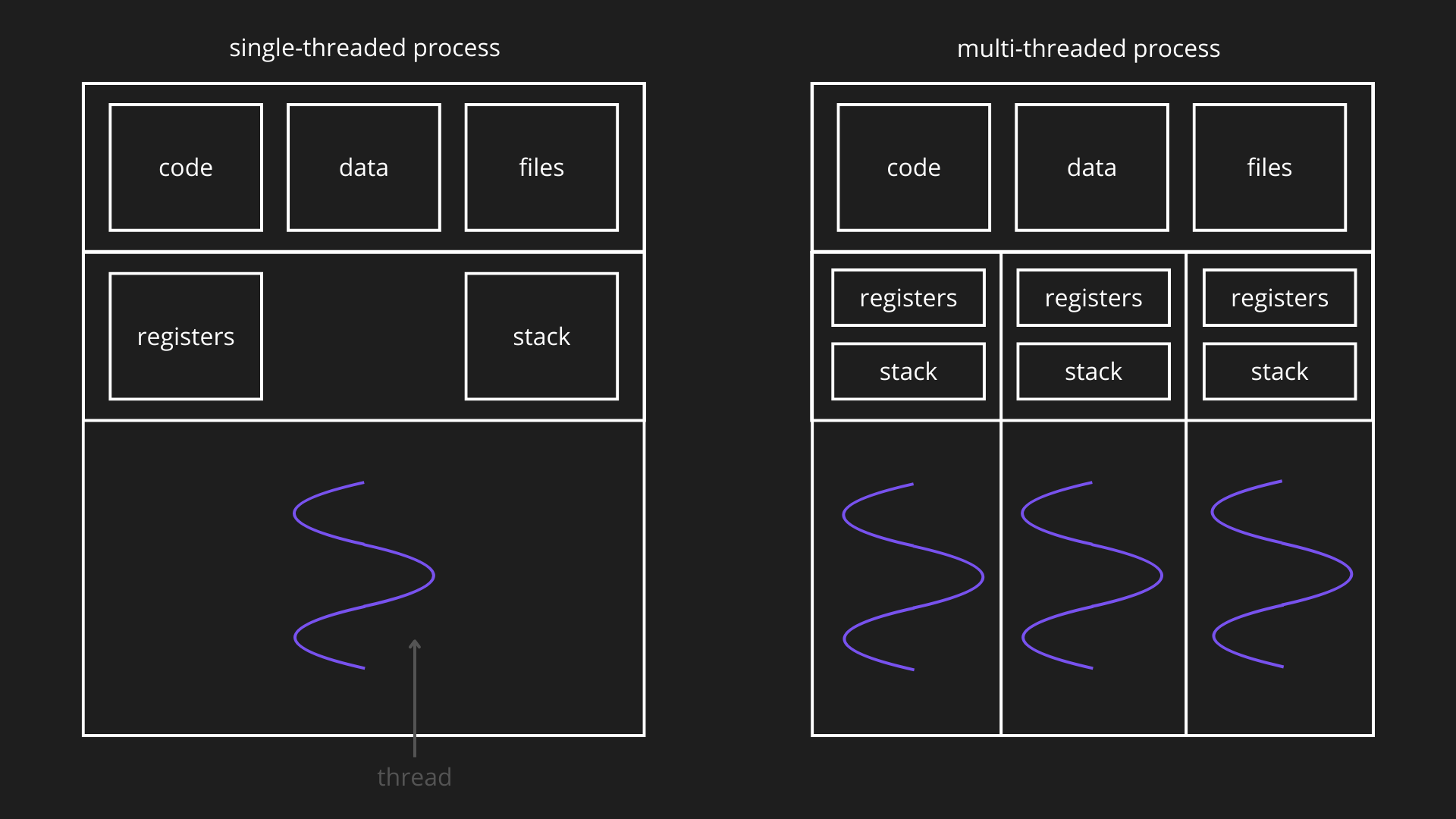
Grazie a questa condivisione, i thread possono cooperare in modo efficiente comunicando direttamente tramite la memoria condivisa, senza necessità di syscall. Tuttavia, la condivisione delle risorse richiede l’uso di meccanismi di sincronizzazione per garantire la correttezza dell’esecuzione concorrente.
Mapping kernel-user thread:
La mappatura kernel-user thread serve a collegare i thread definiti dall’applicazione (user thread), che il kernel non conosce direttamente, ai kernel thread schedulabili dal processore, traducendo la concorrenza logica in esecuzione fisica. Questo permette di controllare il parallelismo, di gestire correttamente i thread che eseguono chiamate bloccanti e di usare in modo efficiente le risorse del sistema. Per gestire il multi-threading vengono utilizzati più modelli:
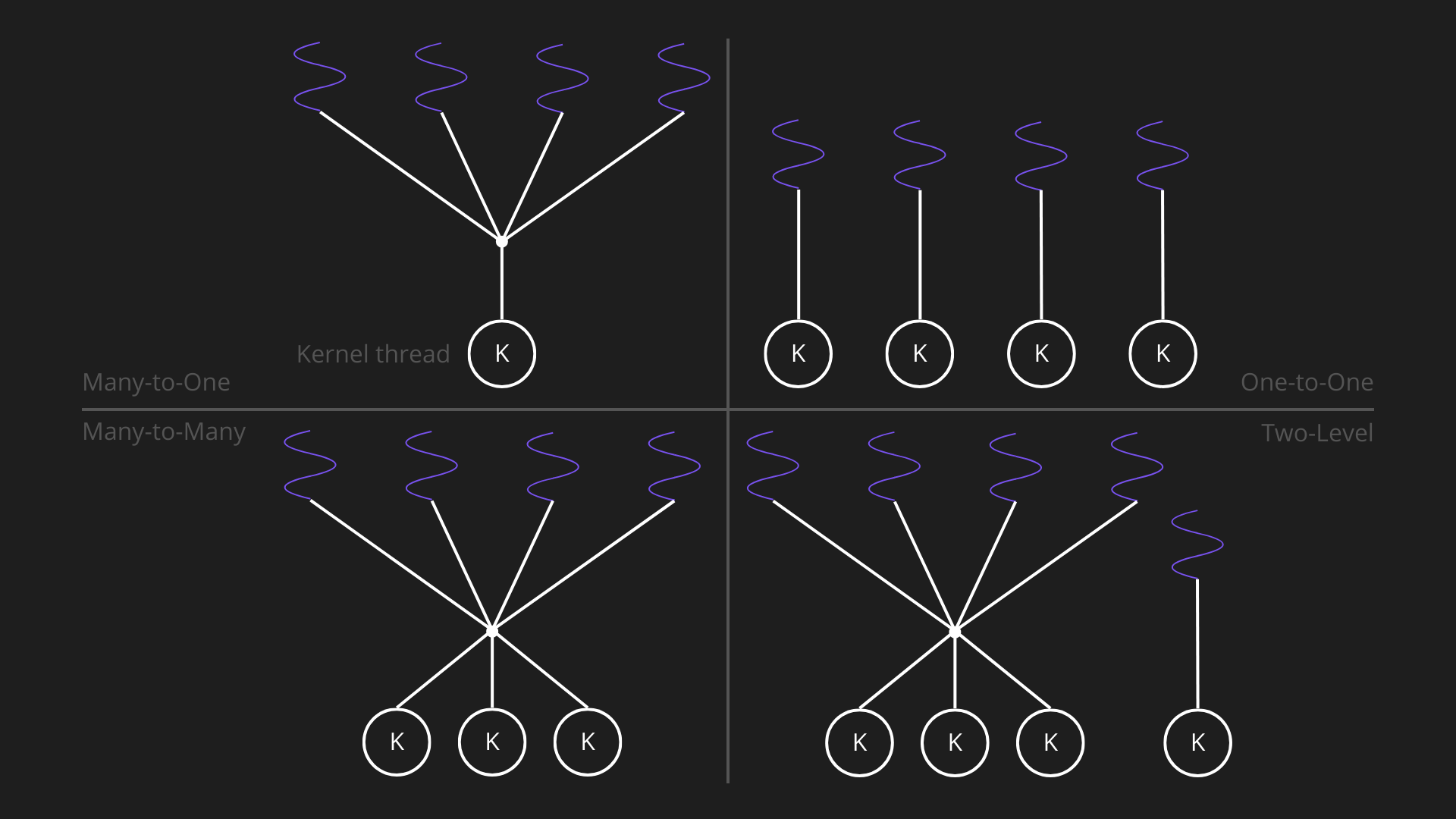
Many-to-One (M:1)
- Mapping: più user thread → 1 kernel thread
- Esecuzione: solo un user thread alla volta può essere eseguito su un core, quindi nessun parallelismo reale.
- Blocchi: syscall bloccante di un thread blocca l’intero processo.
- Livello: puramente user-level.
- Pro: leggero, context switch veloce.
- Contro: non sfrutta più core, problemi con syscall bloccanti.
One-to-One (1:1)
- Mapping: 1 user thread → 1 kernel thread
- Esecuzione: più user thread possono eseguire simultaneamente su più core.
- Blocchi: syscall bloccante di un thread non blocca l’intero processo.
- Livello: puramente kernel-level.
- Pro: supporta parallelismo reale, evita blocchi globali.
- Contro: overhead maggiore, limite al numero di thread creati, kernel più complesso.
Many-to-Many (M:N)
- Mapping: più user thread → più kernel thread
- Esecuzione: il numero di kernel thread può essere ≤ numero di user thread; i processi possono essere suddivisi su più core.
- Blocchi: syscall bloccante non blocca l’intero processo.
- Pro: combina leggerezza dei user thread con parallelismo kernel, numero di thread non limitato.
- Contro: implementazione più complessa (scheduler ibrido).
Two-Level
- Variante di Many-to-Many
- Alcuni thread sono gestiti con One-to-One
- Pro: scheduling più flessibile, permette vantaggi di entrambi i modelli.
- Contro: maggiore complessità implementativa.
LIGHTWEIGHT PROCESS (LWP)
Il Lightweight Process (LWP) è un’entità kernel che funge da ponte tra i kernel thread e i user thread. Quando un evento si verifica (es. I/O completato, timer, syscall), il kernel comunica con la libreria dei thread utente tramite upcall. L’upcall handler nella libreria riceve l’upcall e può associare un nuovo LWP al thread da far eseguire. In pratica, gli LWP permettono ai thread utente di essere notificati e schedulati correttamente dal kernel anche in modelli M:N o M:1.
CONTENTION SCOPE
Quando più thread competono per essere schedulati sulla CPU, il sistema deve decidere come risolvere la competizione. Questo è gestito dal contention scope, che definisce l’ambito della competizione.
Process Contention Scope (PCS)
La competizione avviene tra thread dello stesso processo. Tipico dei modelli Many-to-Many o Many-to-One, dove il kernel non conosce tutti i user thread singolarmente. Lo scheduler utente decide quale thread del processo può eseguire su un LWP disponibile.
System Contention Scope (SCS)
La competizione avviene tra tutti i thread di tutti i processi nel sistema. Tipico del modello One-to-One, dove ogni user thread corrisponde a un kernel thread schedulabile. Lo scheduler del kernel sceglie quale thread eseguire sul core.