Un indexed sequential file (ISAM) è un file fisico che combina i vantaggi dei file sequenziali e degli indici, consentendo sia accessi ordinati che accessi diretti ai record. Si assume che la chiave identifichi univocamente un record.
STRUTTURA
Un ISAM (Indexed Sequential Access Method) prevede l’utilizzo di un file primario che contiene i record e un file indice separato. Il file primario è un file sequenziale diviso in partizioni (o intervalli). Ogni partizione del file primario occupa 1 blocco di dimensione fissa. Ogni blocco contiene:
- un header (metadati, bitmap degli slot)
- una collezione di record
Ogni partizione del file primario è associata ad una entry dell’indice. Ogni entry dell’indice è composta da coppie (K, P):
- K: il valore della chiave di ricerca del primo blocco nella partizione
- P: un puntatore alla posizione fisica del primo blocco della partizione.
L’indice stesso è un file sequenziale ordinato per chiave K di ricerca.
N.B. Il puntatore può essere di due tipi: Block pointer: punta all’indirizzo fisico del blocco. Record pointer: combina l’indirizzo del blocco e l’ID del record o l’offset all’interno del blocco.
TIPI DI INDICE
- Dense index: contiene un’entry per ogni valore possibile della chiave (1 partizione = 1 record, quindi 1 entry per record)
- Sparse index: contiene un’entry solo per alcuni valori della chiave (1 partizione = 1 blocco, quindi 1 entri per blocco)
N.B. Il dense index ha accessi più veloci ma risulta molto più pesante e complesso rispetto a uno sparse index, che invece è molto più piccolo.
FUNZIONAMENTO
Inserimento
Inserire un nuovo record richiede:
- cercare nel file indice la voce più vicina alla chiave desiderata
- accedere direttamente al blocco o record indicato dal puntatore
- eventuale ricerca sequenziale locale all’interno della partizione per trovare il record esatto
Ricerca
Come per il sequential file la ricerca può essere sequenziale e binaria, tuttavia, la struttura indicizzata del file ISAM, permette anche la ricerca per indice:
Linear search:
Scansione sequenziale dei blocchi con possibilità di stop condizionato.
Costo medio:
In un file con NBK blocchi:
- ⌈NBK / 2⌉ accessi (in media)
- tutti SBA
N.B. Stop condizionato: se si incontra un record con chiave maggiore (o minore) di quella cercata, la ricerca può terminare in quanto i record sono ordinati (evita full scan del file nella maggior parte dei casi).
Binary search:
Approccio possibile perché il file è ordinato (guarda il funzionamento dell’algoritmo di ricerca binaria).
Costo medio:
In un file con NBK blocchi:
- ⌈log2(NBK)⌉ accessi
- tutti RBA
Index based search:
Utilizzo dell’indice primario, cercando la entry associata alla partizione che contiene il record di interesse. Si può ad esempio svolgere una binary search sull’indice (che in genere è molto più piccolo del file primario).
Costo medio:
In un indice con NBKindex blocchi:
- ⌈log2(NBKindex)⌉ + 1 (binary search sull’indice + accesso alla partizione giusta nel primary file)
- tutti RBA
Esempio:
Primary file:
NR = 30.000 record, RS = 100 bytes, BKS = 2048 bytes NRpBK = ⌊BKS/RS⌋ = 20 record per blocco NBK = 30.000 / 20 = 1.500 blocchi
Primary index:
1 index entry per blocco dati ES (entry size) = 15 bytes NEpBKindex = ⌊BKS/ES⌋ = 136 entry per blocco NBKindex = ⌈NBK / NRpBKindex⌉ = 12
Binary search sul file primario → log₂(1500) ≈ 11 RBA Binary search sull’indice → log₂(12) + 1 ≈ 5 RBA
N.B. La ricerca sull’indice è molto più veloce in quanto NBKindex << NBK.
ESEMPIO
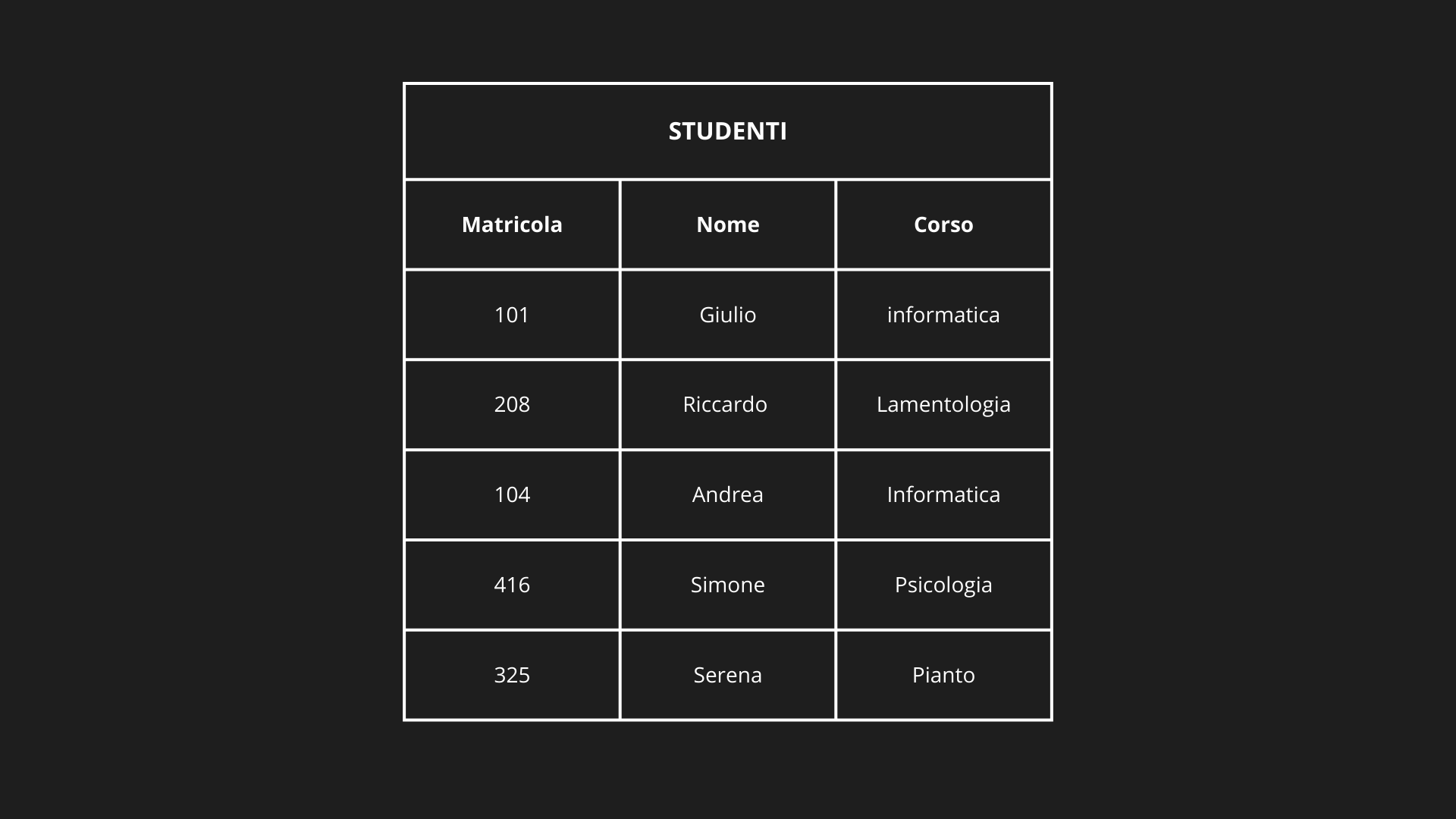 Indexed sequential file:
Indexed sequential file:
- Capacità partizione (NRpBT) = 2 record per partizione
INDEXED SEQUENTIAL FILE
INDEX FILE (Sparse)
├─ Key=101 → Block 1 # 101 e 104
├─ Key=208 → Block 2 # 208 e 325
└─ Key=416 → Block 3 # 416
PRIMARY FILE
|
├─ BLOCK 1 [Header: num_records=2]
| ├─ Record: 101, Giulio, Informatica
| └─ Record: 104, Andrea, Informatica
|
├─ BLOCK 2 [Header: num_records=2]
| ├─ Record: 208, Riccardo, Lamentologia
| └─ Record: 325, Serena, Pianto
|
└─ BLOCK 3 [Header: num_records=2]
└─ Record: 416, Simone, Psicologia