Un hash file usa una funzione di hashing per ottenere accesso diretto ai record, riducendo drasticamente il numero di accessi a blocco, a costo di non supportare ricerche ordinate o per intervalli.
STRUTTURA
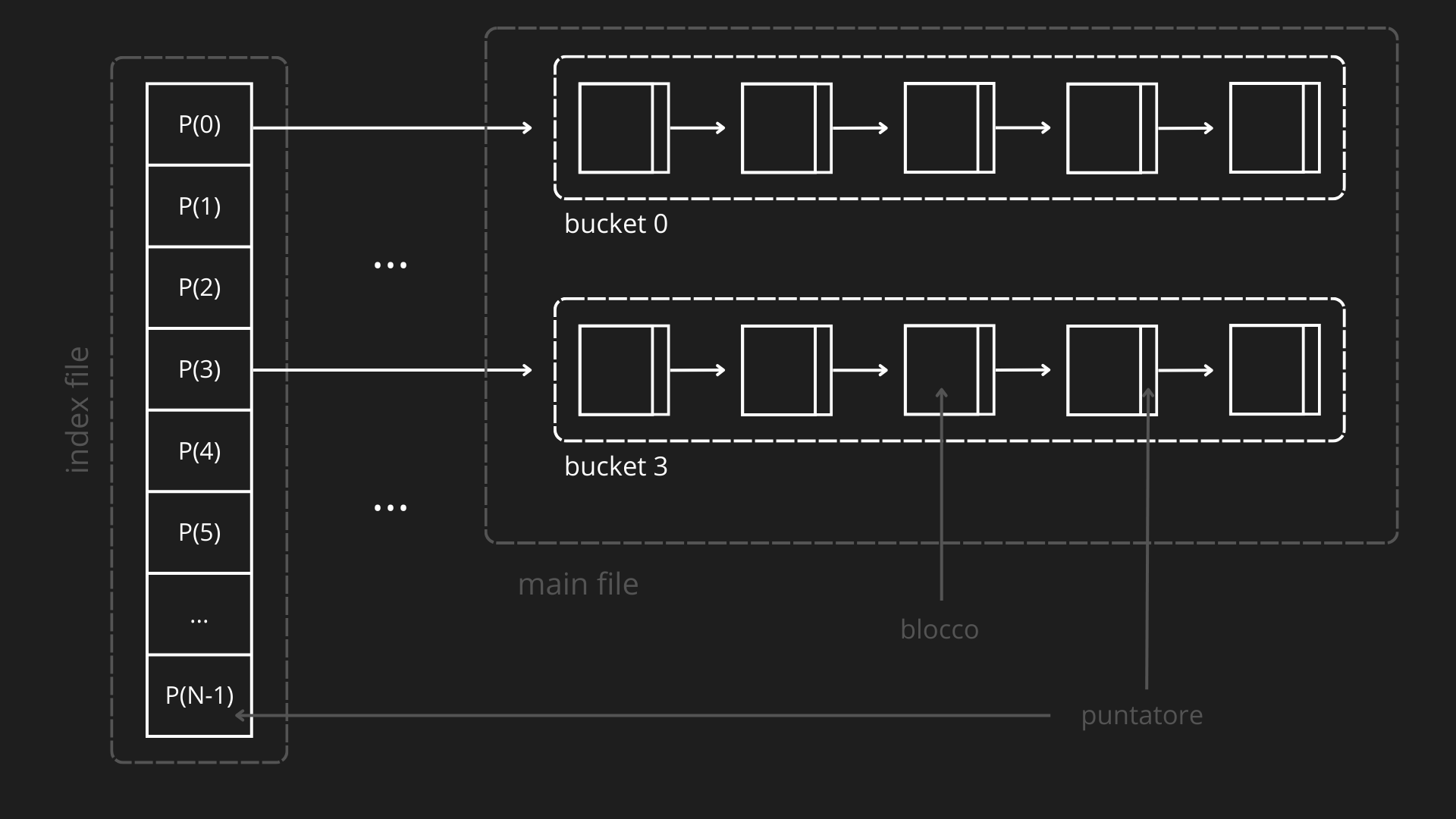
Un hash file è composto da:
- Un file indice (o bucket directory), che contiene una tabella hash con puntatori ai bucket del file principale
- Un file principale, che contiene i blocchi divisi per bucket
Ogni blocco contiene:
- un header (metadati, bitmap degli slot)
- una collezione di record
- un puntatore al blocco successivo nel bucket
Un algoritmo di hashing trasforma il valore della chiave in un indirizzo di bucket. I record con chiavi che producono lo stesso valore hash sono memorizzati nello stesso bucket.
PARAMETRI
Numero massimo di record che un blocco può contenere:
Dove:
- BKS = dimensione del blocco (in byte)
- PS = dimensione dei puntatori (in byte)
- RS = dimensione dei record (in byte)
Numero medio atteso di record che un bucket può contenere:
Dove:
- NR = numero totale di record del file
- NBT = numero totale di bucket nel file
Numero di blocchi che occupa un bucket:
Dove:
- NRpBT = numero di record per bucket
- NRpBK = numero di record per blocco
Il loading factor indica quanto è pieno un bucket in media:
Tipicamente tra 0.7 e 0.9.
FUNZIONAMENTO
Hashing e indirizzamento
Un hash function definisce la trasformazione:
address(keyi) = keyi mod M
- M = numero di indirizzi hash possibili (spesso un numero primo vicino ma leggermente più grande di NBT)
- il resto (mod) della divisione determina il bucket di destinazione
L’obiettivo è ottenere una distribuzione uniforme delle chiavi sui bucket.
N.B. La mappatura attraverso la funzione hash porta inevitabilmente a generare collisioni e overflow: problemi logici dei file hash.
Inserimento
Inserire un nuovo record richiede:
- calcolare l’hash della chiave
- accedere direttamente al bucket corrispondente
- se il bucket corrispondente ha spazio: inserimento immediato
- se il bucket è pieno: gestione dell’overflow (dipende dalla tecnica adottata)
Costo medio:
- 2 accessi (1 lettura + 1 scrittura dell’ultimo blocco)
- quasi sempre RBA
Ricerca
La struttura indicizzata permette accessi diretti ai blocchi:
Hashing e indexing:
- calcolare l’hash della chiave
- accedere direttamente al primo blocco del bucket
- scansionare i blocchi del bucket fino a trovare il record, oppure fino a fine bucket
- se il record non è nel bucket primario, esplorare eventuali blocchi di overflow
Costo medio:
Poiché ciascun bucket è organizzato come un heap file, una ricerca all’interno del bucket richiede in media la lettura di metà dei suoi blocchi. Se NBKpBT è il numero di blocchi del bucket:
- ⌈NBKpBT/2⌉ accessi, a cui va eventualmente aggiunto l’accesso alla bucket directory se non residente in memoria.
Il primo di questi accessi è RBA per il bucket primario, i successivi sono SBA (se contigui) o RBA (se allocati altrove).
Eliminazione
Prima si individua il record (ricerca) poi si sovrascrive o cancella dal blocco
Costo medio:
Se NBKpBT è il numero di blocchi del bucket:
- chiave unica: ⌈NBKpBT/2⌉ accessi + 1 scrittura (RBA)
- chiave non unica: NBKpBT accessi + eventuali scritture nei blocchi contenenti record da cancellare
Modifica
Prima si individua il record (ricerca) poi si aggiorna nel blocco
Costo medio:
Se NBKpBT è il numero di blocchi del bucket:
- chiave unica: ⌈NBKpBT/2⌉ accessi + 1 scrittura (RBA)
- chiave non unica: NBKpBT accessi + scritture nei blocchi contenenti record da modificare
ESEMPIO
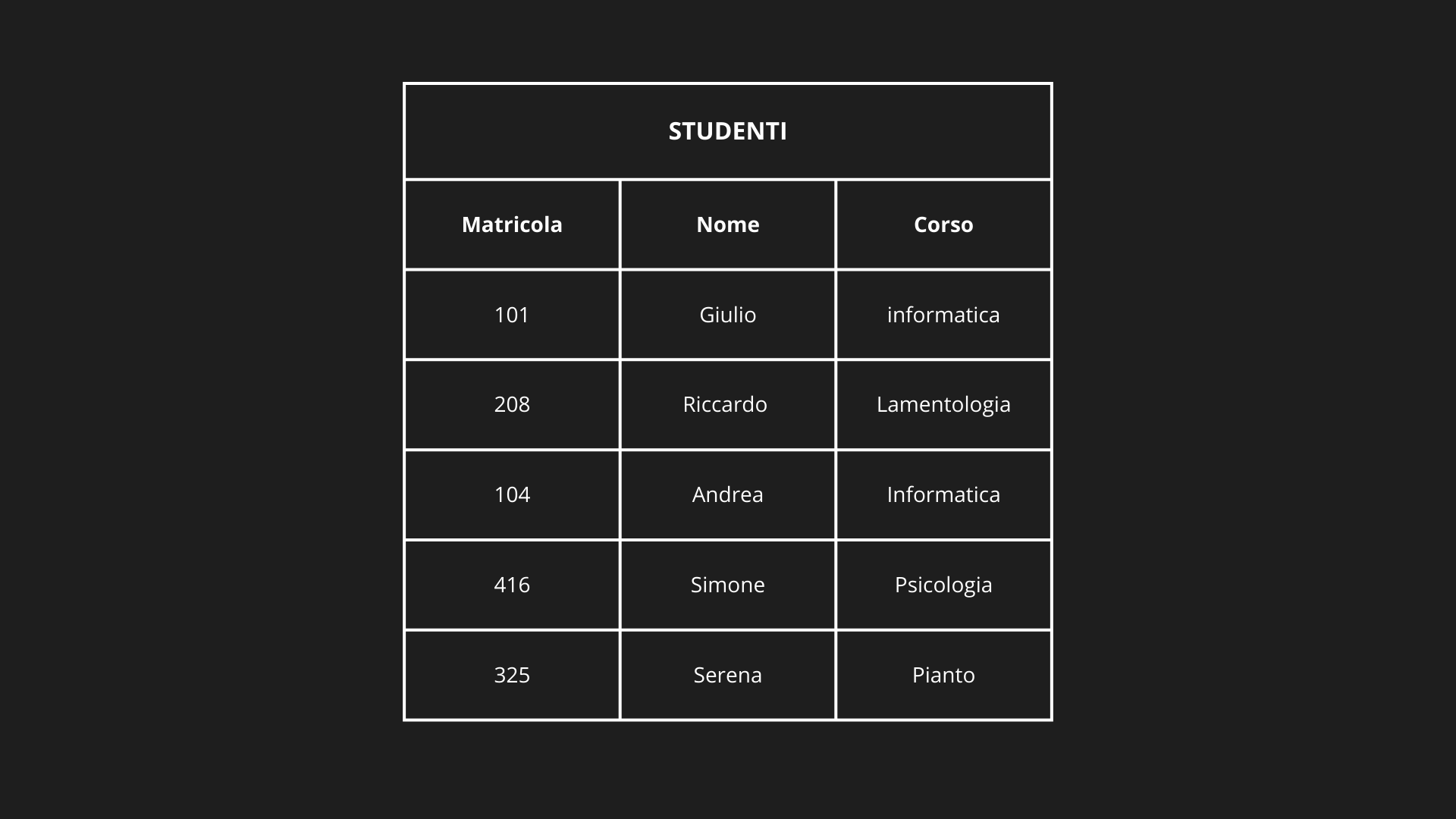 Hash file:
Hash file:
- Capacità bucket (NRpBT) = 2 record per bucket
- NR = 5 record → NBT = ⌈5/2⌉ = 3 bucket minimi necessari
- Scegliamo M = 5 (numero primo > NBT)
HASH FILE
BUCKET DIRECTORY
|
├─ Key=0 → Bucket 0 # 325/5 da resto 0
├─ Key=1 → Bucket 1 # 101/5 e 416/5 danno resto 1
├─ key=2 → Bucket 2 # vuoto
├─ Key=3 → Bucket 3 # 208/5 da resto 3
└─ Key=4 → Bucket 4 # 104/5 da resto 4
MAIN FILE
|
├─ BUCKET 0 [Blocco 1, Header: num_records=1]
| └─ Record: 325, Serena, Pianto
|
├─ BUCKET 1 [Blocco 2, Header: num_records=2]
| ├─ Record: 101, Giulio, Informatica
| └─ Record: 416, Simone, Psicologia
|
├─ BUCKET 3 [Blocco 3, Header: num_records=1]
| └─ Record: 208, Riccardo, Lamentologia
|
└─ BUCKET 4 [Blocco 4, Header: num_records=1]
└─ Record: 104, Andrea, Informatica