Un database è una raccolta strutturata di dati mutualmente connessi, memorizzata elettronicamente. Gli insiemi di dati, all’interno di un DB, sono organizzati in diverse strutture che ne facilitano la creazione, l’accesso e l’aggiornamento ed ottimizzano la gestione delle risorse fisiche. I sistemi software che permettono di gestire facilmente questi dati sono i DBMS.
LIVELLI DI ASTRAZIONE
I livelli di astrazione di un database descrivono come i dati sono visti e gestiti a diversi gradi di dettaglio. Servono a separare la visione logica da quella fisica, garantendo indipendenza e flessibilità.
Si distinguono tre livelli principali, tutti e 3 indipendenti (secondo il modello ANSI/SPARC):
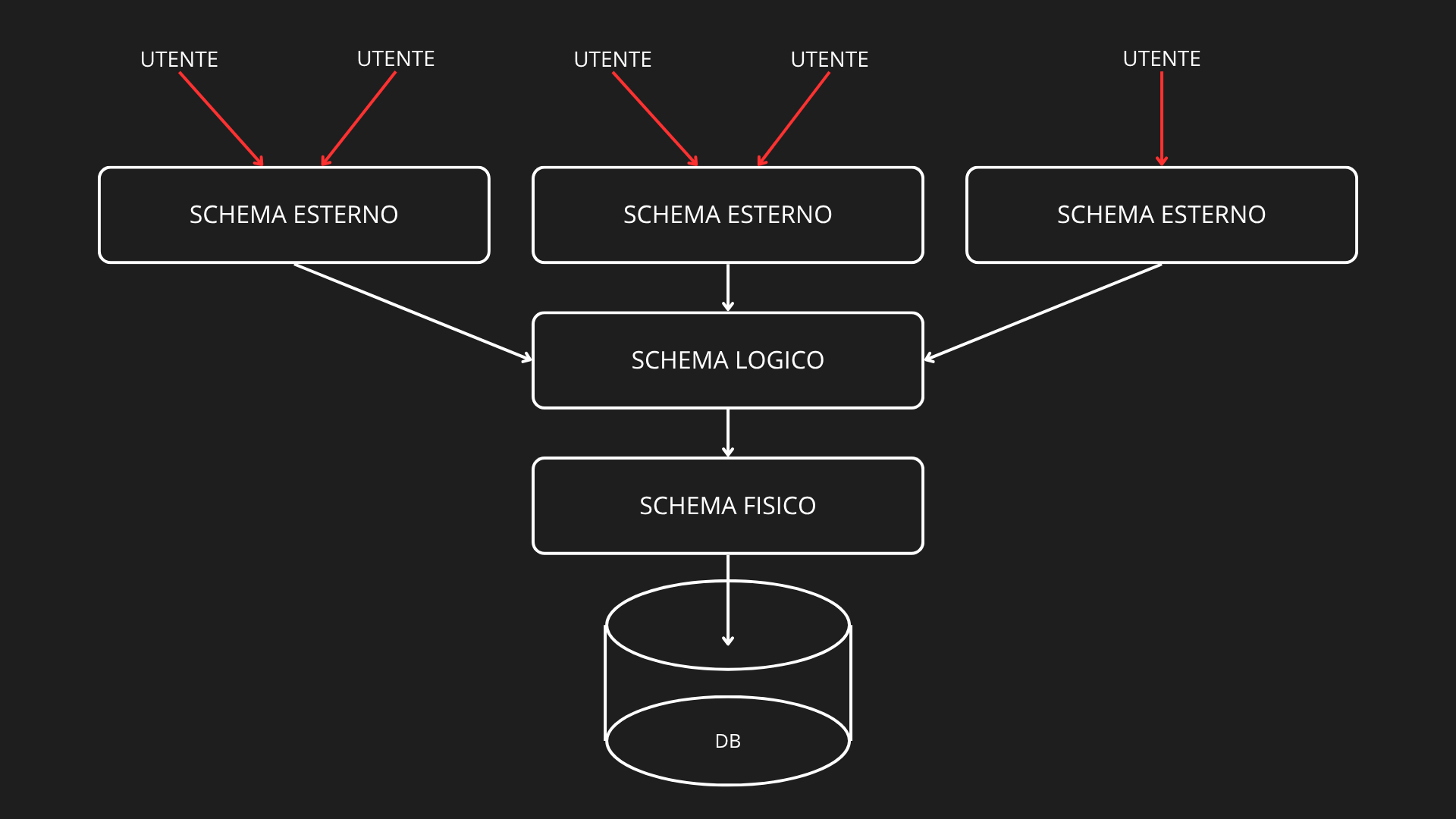
Livello esterno (external schema)
Rappresenta come l’utente vede i dati. Ogni utente può avere una vista personalizzata del database (solo i dati di suo interesse). Fornisce sicurezza e semplicità, nascondendo informazioni non necessarie.
Esempio: un docente vede solo gli studenti del suo corso.
Livello logico (conceptual schema)
Descrive la struttura logica globale del database (logical layer). Definisce entità, attributi, relazioni, vincoli e tipi di dato. Non specifica come i dati sono memorizzati fisicamente. È il livello su cui lavora il DBA (Database Administrator) per progettare lo schema logico.
Esempio: tabelle Studenti, Corsi, Esami e relazioni tra loro.
Livello fisico (internal schema)
Descrive come i dati sono effettivamente memorizzati nei dispositivi di memoria (physical layer). Specifica file, indici, pagine, blocchi, strutture di accesso. È gestito dal DBMS, invisibile agli utenti.
Esempio: dati salvati in file binari con indici B-tree per ricerche più rapide.
CARATTERISTICHE
Un DB deve supportare memorizzazione efficiente, gestione di grandi quantità di dati, ridondanza minima e indipendenza dei dati. Deve permettere uso concorrente da parte di più utenti e deve fornire meccanismi di recupero e ripristino in caso di guasti.
Sicurezza (security)
Protezione dei dati da accessi non autorizzati, alterazioni o cancellazioni indebite. Autenticazione (chi accede), autorizzazione (cosa può fare), controllo accessi (ruoli, permessi). Crittografia, backup, audit logging sono strumenti comuni.
Integrità (integrity)
Garantisce che i dati siano legali (corretti, validi e coerenti con i vincoli definiti). Le transazioni devono portare il database da uno stato valido a un altro stato valido (consistency).
Vincoli di integrità:
I vincoli di integrità sono condizioni logiche che servono a garantire la correttezza e la coerenza dei dati in un database relazionale. Si dividono in vincoli intra-relazionali (dentro una sola tabella) e vincoli inter-relazionali (tra più tabelle). Vediamoli nel dettaglio:
Vincolo di dominio (intra):
Ogni attributo deve avere valori compatibili col suo dominio (tipo di dato e regole associate).
Esempio:
Età ≥ 0
Data_Nascita deve essere una data valida.
Vincolo di chiave (intra):
Serve a identificare in modo univoco ogni tupla. La chiave primaria (primary key) non può essere NULL e deve essere unica. Possono esserci anche chiavi candidate (altre combinazioni univoche possibili).
Esempio:
Matricola è chiave primaria in Studenti.
Vincolo di nullabilità (intra):
Stabilisce se un attributo può assumere valore NULL oppure no.
Esempio:
Nome NOT NULL → ogni studente deve avere un nome.
Vincoli generali o di check (intra):
Condizioni logiche espresse liberamente, spesso con CHECK.
Esempio:
CHECK (Età BETWEEN 18 AND 120).
Vincolo di integrità referenziale (inter):
Garantisce che un valore in una tabella esista anche in un’altra.
Si basa su chiavi esterne (foreign key).
Esempio:
Esami(Studente) fa riferimento a Studenti(Matricola).
Ogni valore di Studente in Esami deve esistere in Matricola di Studenti.
Se si prova a inserire o cancellare dati che violano il vincolo, il DBMS blocca l’operazione o aggiorna le tabelle in cascata (ON DELETE CASCADE, ON UPDATE SET NULL).
Transazioni (transactions)
Una transazione è un’unità logica di lavoro che consiste in una o più operazioni (lettura, scrittura). Una transazione valida ha le seguenti proprietà:
- Atomicità: o tutte le operazioni hanno successo o nessuna viene mantenuta.
- Coerenza (Consistency): la transazione porta il DB da uno stato valido ad un altro valido, rispettando vincoli.
- Isolamento (Isolation): transazioni concorrenti non devono interferire mostrando stati intermedi.
- Durabilità (Durability): una volta che una transazione è stata confermata (commit), i suoi effetti sono permanenti anche in caso di guasto.
Ripristino (Recovery)
Meccanismi per riportare il database a uno stato coerente dopo un errore o un guasto. Log delle transazioni, checkpoint, backup e operazioni di undo/redo sono strumenti tipici.
Concorrenza (Concurrency)
Permette a più utenti o processi di accedere e modificare i dati contemporaneamente senza compromettere integrità o coerenza. Tecniche principali: lock-based (blocco di record, tabelle), timestamp, MVCC. Problemi da gestire: dirty reads, non-repeatable reads, phantom reads.